FinOps Inform · Cost Optimisation
Cloud cost attribution for microservices: 2026 guide
Unlock savings with cloud cost attribution for microservices. Learn to track expenses accurately and boost accountability in your organization.

Cloud cost attribution for microservices is the process of mapping every cloud expenditure back to the individual service, team, or product that generated it, using billing exports, telemetry, and service metadata as inputs. Without this mapping, 27% of cloud spend is wasted because leadership cannot see costs by service owner. The industry term for this discipline is cost allocation, and it sits at the heart of the FinOps framework. Koritsu AI works with engineering teams to build exactly this kind of visibility, turning opaque cloud bills into per-service financial accountability.
What are the prerequisites for cloud cost attribution in microservices?
Accurate cost attribution starts with the right data sources in place before you write a single allocation rule. You need four inputs: cloud billing exports from AWS Cost and Usage Reports, Google Cloud Billing Export, or Azure Cost Management; runtime telemetry from your service mesh or observability platform; service metadata from a configuration management database (CMDB) or service catalogue; and identity and access management (IAM) data that maps principals to services.
Consistent tagging is the foundation, but it is not sufficient on its own. Every resource must carry tags for service name, team, environment, and cost centre. Naming conventions must be enforced at the infrastructure-as-code layer, not applied retrospectively. Without this discipline, your attribution pipeline will produce results that engineers distrust and finance cannot audit.
Organisational readiness matters as much as tooling. Finance, platform engineering, and product teams must agree on what a "service" means before any allocation model runs. A shared data dictionary, even a simple one maintained in Confluence or Notion, prevents the definitional disputes that derail attribution projects six months in.

| Data input | Source | Purpose |
|---|---|---|
| Billing exports | AWS CUR, GCP Billing Export, Azure Cost Management | Raw spend by resource |
| Runtime telemetry | Service mesh (Istio, Linkerd), eBPF agents | Actual consumption per service |
| Service metadata | CMDB, service catalogue | Maps resources to owners |
| IAM data | Cloud provider identity logs | Links principals to services |
Pro Tip: Enforce tags via policy-as-code tools such as Open Policy Agent or AWS Service Control Policies. Tagging after deployment recovers only a fraction of the coverage you get from blocking untagged resources at creation.
How to build a cloud cost attribution pipeline for microservices
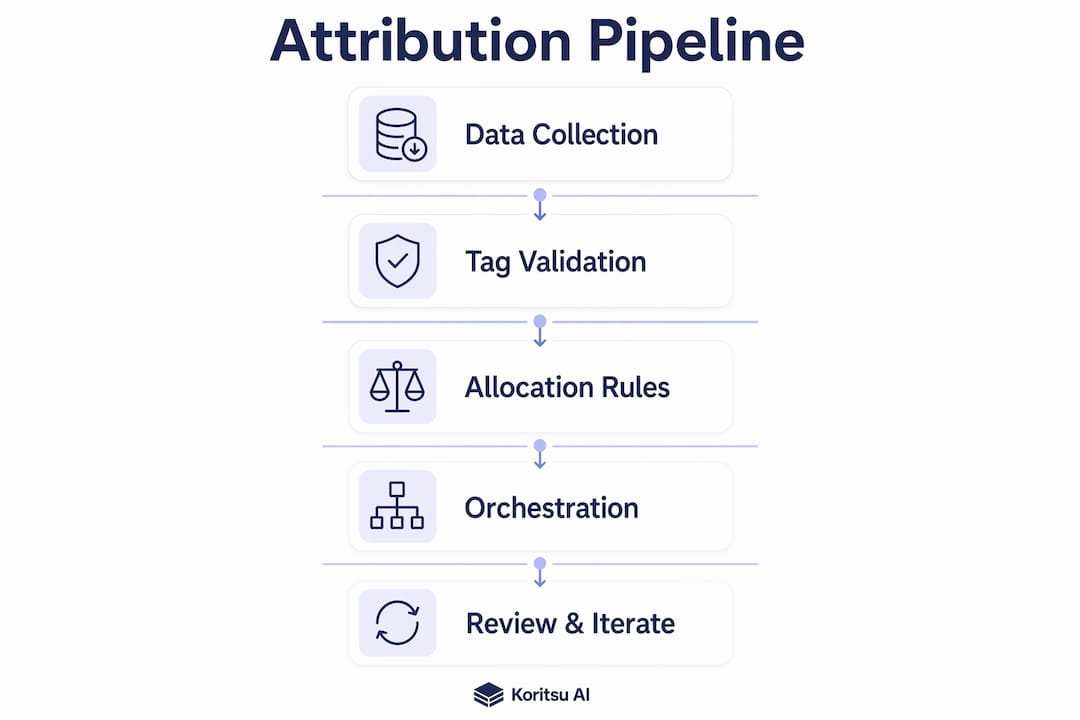
A cost attribution engine ingests billing and telemetry data, normalises it, maps costs to services, enriches the result with business context, allocates using a chosen model, and reconciles against invoices. Each step is distinct. Skipping one produces gaps that compound downstream.
-
Ingest. Pull billing exports on a daily cadence. Ingest telemetry from your service mesh or eBPF agent at the same frequency. Store both in a queryable data warehouse such as BigQuery or Amazon Redshift.
-
Normalise. Standardise resource identifiers, currencies, and time zones across providers. Deduplicate records where the same resource appears in multiple billing line items. This step is where multi-cloud environments create the most friction.
-
Map. Join billing records to service metadata using tags, IAM principals, and service mesh trace data. Relying solely on billing tags underreports shared infrastructure usage. Runtime telemetry from service mesh tracing or eBPF traffic observation is essential for accurate attribution in microservices.
-
Enrich. Attach business context: product line, team name, squad, and environment. This transforms a cost record from "EC2 instance i-0abc123" into "Payments service, checkout squad, production."
-
Allocate. Apply your chosen allocation model. Direct allocation assigns costs where a resource serves one service exclusively. Proportional allocation splits shared costs by a usage metric such as CPU seconds or request count. Amortised allocation spreads reserved instance or committed use discount costs across the reservation period.
-
Reconcile. Compare allocated totals against the actual invoice. Residual costs, those that cannot be attributed to any service, must be tracked separately and reviewed each cycle. Boeing achieved savings of over $958,000 annually by combining telemetry and CMDB data in a multi-step attribution method of this kind.
| Allocation model | Best fit | Limitation |
|---|---|---|
| Direct | Dedicated resources per service | Does not handle shared infra |
| Proportional | Shared databases, gateways | Requires reliable usage metrics |
| Amortised | Reserved instances, savings plans | Obscures month-to-month variance |
Pro Tip: Build your pipeline as a directed acyclic graph (DAG) in Apache Airflow or a similar orchestrator. This makes each step auditable and rerunnable when upstream data changes.
What organisational practices drive successful cost attribution adoption?
The organisational challenge in cost attribution is 80% behavioural and only 20% technical. Engineering teams that have never seen a cloud bill resist attribution because it feels like surveillance. Finance teams that have never read a service mesh trace resist it because the data feels unreliable. Closing that gap requires deliberate process design.
Start with showback, not chargeback. Showback means teams see their costs without any financial consequence. It builds familiarity with the data and surfaces errors before money changes hands. Chargeback, where costs are actually transferred between cost centres, comes later once the data has earned trust.
76% of microservices organisations treat platform engineering as overhead rather than allocating its costs back to consumer teams. The result is predictable: heavy consumers of shared services pay the same as light ones, removing any incentive to write efficient code. Allocating platform team costs back to consumer teams corrects this misalignment.
Run a shadow model for 2–3 months before activating real chargeback. Generate phantom bills from existing ticket or Jira label data and share them with teams. This approach validates consumption data and reduces platform ticket volume by 12–18% once real chargeback goes live, because teams have already resolved attribution disputes during the shadow period.
Best practices for organisational adoption:
- Assign a named cost owner to every service in the service catalogue.
- Include cloud spend as a standing agenda item in sprint reviews.
- Publish a weekly cost digest by team, not just a monthly finance report.
- Define an escalation path for disputed attributions before chargeback goes live.
- Treat unattributed spend as a bug, not an acceptable residual.
How to troubleshoot and refine your attribution pipeline
Untagged resources are the most common failure mode. When a resource carries no tag, the pipeline cannot map it to a service, and it lands in a catch-all "unattributed" bucket. The fix is upstream: block untagged resource creation using service control policies, and run a weekly report that flags any resource older than 48 hours without a valid service tag.
Shared infrastructure creates the second category of problems. A Kubernetes cluster running 40 services cannot be attributed by tags alone. The correct approach is to use runtime telemetry such as service mesh metrics or eBPF data to measure actual CPU, memory, and network consumption per pod, then allocate node costs proportionally. Cloud Cost Intelligence platforms integrate telemetry with billing data to provide per-service visibility within existing engineering tools, which reduces the gap between what billing reports and what services actually consume.
Telemetry accuracy must be validated against billing data on a regular cycle. If your service mesh reports that the payments service consumed 30% of cluster CPU but billing shows a cost that implies 50%, the discrepancy points to either a telemetry gap or a billing anomaly. Both need investigation. Treat the reconciliation step as a quality gate, not a formality.
Multi-cloud and hybrid environments multiply complexity. Each provider uses different resource identifiers, billing granularities, and discount mechanisms. Normalisation at the ingestion step must account for these differences explicitly. A common mistake is to normalise currencies and time zones but leave resource identifiers in provider-native formats, which breaks the mapping step when a service spans AWS and GCP.
Continuous improvement requires a feedback loop. Review unattributed spend monthly. Track the percentage of total spend that is attributed to a named service, and set a target. Most mature FinOps teams target attribution coverage above 90%. Use cloud cost per feature analysis to identify which services are improving their unit economics and which are regressing.
Key takeaways
Effective cloud cost attribution in microservices requires a six-step pipeline, telemetry beyond tags, and organisational practices that treat cost as a shared engineering responsibility.
| Point | Details |
|---|---|
| Telemetry over tags | Service mesh or eBPF data is required to attribute shared infrastructure costs accurately. |
| Six-step pipeline | Ingest, normalise, map, enrich, allocate, and reconcile in sequence for auditable results. |
| Start with showback | Show teams their costs before charging them to build trust and catch data errors early. |
| Platform cost allocation | Allocating platform engineering costs to consumer teams removes the incentive for inefficient usage. |
| Shadow run first | Running phantom bills for 2–3 months before chargeback reduces disputes and ticket volume post-launch. |
Cost attribution is a process problem, not a technology problem
I have reviewed attribution pipelines across dozens of engineering organisations, and the pattern is consistent. Teams that fail at cost attribution do not fail because they chose the wrong tool. They fail because they never agreed on what a service boundary means, or because finance and engineering never sat in the same room to define the allocation rules.
The technology is genuinely the easier part. A well-configured data warehouse, a service mesh emitting trace data, and a DAG-based pipeline will get you to 80% attribution coverage within a quarter. The remaining 20%, the shared databases, the legacy monolith components, the platform services with no clear consumer, requires negotiation and organisational will.
My strongest recommendation is to treat telemetry integration as non-negotiable from day one. Teams that rely on tags alone spend months patching gaps that telemetry would have prevented. Service mesh data gives you consumption at the request level. eBPF gives you network and CPU at the kernel level. Neither requires application code changes. There is no good reason to skip them.
The future of this discipline is AI-assisted attribution. Koritsu AI's agent, Kori, already surfaces cost anomalies and misattributed spend automatically, reducing the manual review burden that makes attribution feel unsustainable at scale. The organisations that embed this kind of continuous analysis into their engineering workflow will have a structural cost advantage over those that treat attribution as a quarterly finance exercise.
How Koritsu AI supports engineering-grade cost attribution
Koritsu AI combines a continuous analysis platform with hands-on specialist support to help engineering teams build and operate attribution pipelines that actually hold up in production. Kori, the AI agent, surfaces misattributed spend and cost anomalies in real time, so your team spends less time debugging the pipeline and more time acting on the findings. A UK bidding platform achieved a 52% reduction in cloud costs after working with Koritsu AI to implement telemetry-driven attribution across a complex microservices environment. The engagement starts with a free assessment, and Koritsu AI charges only on savings delivered. Explore the cloud cost optimisation platform to see how it applies to your architecture.
FAQ
What is cloud cost attribution in microservices?
Cloud cost attribution in microservices is the process of mapping cloud expenditure to individual services using billing exports, telemetry, and service metadata. It is the operational implementation of cost allocation within a FinOps framework.
Why are billing tags not enough for microservices cost attribution?
Tags cannot capture how shared infrastructure is consumed across services. Runtime telemetry from service meshes or eBPF agents measures actual CPU, memory, and network usage per service, which is the only reliable basis for attributing shared costs accurately.
What is the difference between showback and chargeback?
Showback displays costs to teams without financial consequence, building familiarity and trust. Chargeback transfers those costs between budget holders. The FinOps best practice is to run showback first, then move to chargeback once data accuracy is validated.
How do I handle platform engineering costs in attribution?
Allocate platform engineering costs back to the consumer teams based on their proportional usage of shared services. Treating platform costs as undifferentiated overhead means heavy consumers pay the same as light ones, which removes the financial signal that drives efficient engineering.
How long does it take to implement a cost attribution pipeline?
A basic pipeline covering tagged resources can be operational within four to six weeks. Full telemetry integration and organisational chargeback adoption typically takes three to six months, including the shadow run period needed to validate data and resolve disputes before real financial transfers begin.