FinOps Inform · Cost Optimisation
Cloud resource lifecycle: a guide for engineers in 2026
Discover what is cloud resource lifecycle and how it helps engineers manage assets efficiently. Optimize costs and improve performance in 2026.

The cloud resource lifecycle is defined as the end-to-end management framework that governs a cloud asset from initial planning through to final decommissioning. Most cloud cost problems are not pricing problems. They are lifecycle problems. Resources get provisioned without exit plans, run past their useful life, and quietly drain budgets. Understanding the six lifecycle stages gives engineering teams the structure to prevent that. This guide covers each stage, the tools that support them, and the management practices that separate efficient cloud estates from expensive ones.
What is the cloud resource lifecycle?
The cloud resource lifecycle is the structured sequence of stages every cloud asset passes through, from the moment it is requested to the moment it is decommissioned. The industry term for managing this sequence is IT asset lifecycle management, though cloud teams often use "cloud resource lifecycle management" to describe the same discipline applied specifically to cloud infrastructure. Both terms refer to the same core practice: tracking and governing assets across their entire lifespan.
Lifecycle management succeeds when treated as a continuous, automated workflow rather than a manual process. That distinction matters. Manual tracking breaks down at scale. A team managing hundreds of EC2 instances, storage buckets, and managed services across AWS, Google Cloud, and Azure cannot rely on spreadsheets or tribal knowledge to stay on top of resource states. Automation and governance tooling are not optional extras. They are the foundation.
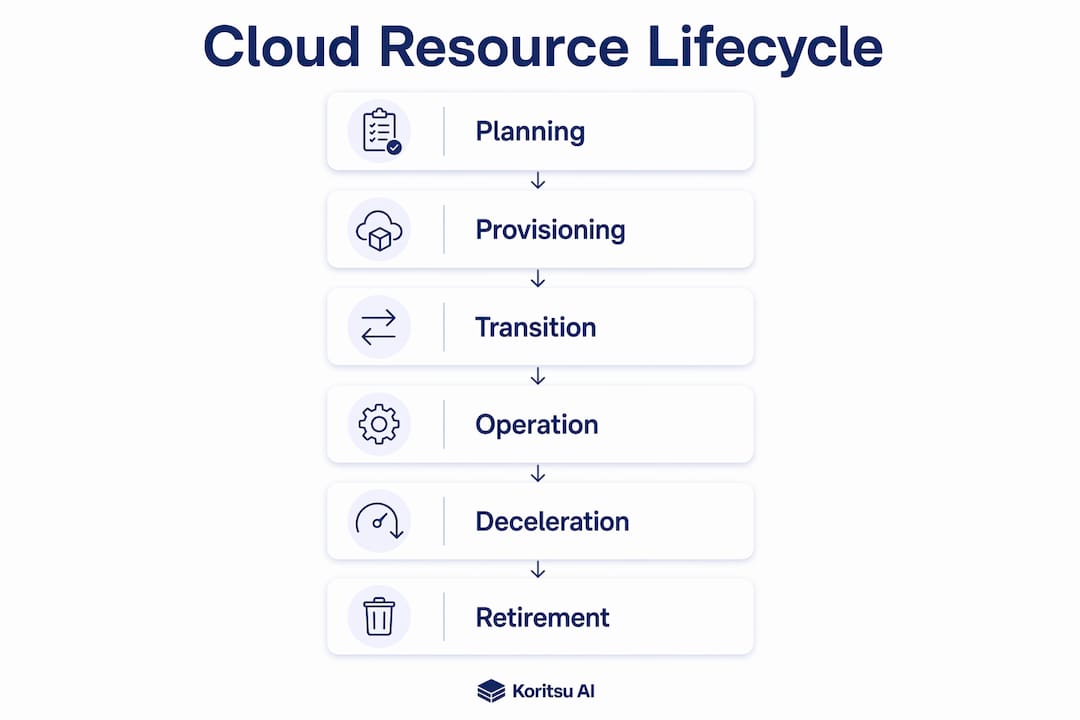
The six stages identified across cloud infrastructure frameworks are: Planning, Provisioning, Transition, Operation, Decline, and Retirement. Each stage has distinct activities, ownership requirements, and cost implications. Skipping or mismanaging any one of them creates compounding problems downstream.

What are the key stages of the cloud resource lifecycle?
Understanding each stage in sequence gives you a clear picture of where management effort is required and where cost risk accumulates.
-
Planning. This stage defines the business need, selects the appropriate service type, and sets sizing parameters. Poor planning is the root cause of overprovisioning. Teams that skip a formal sizing exercise routinely deploy instances two to three times larger than the workload requires.
-
Provisioning (Introduction). The resource is created and onboarded. This is the critical moment for tagging, CMDB registration, and cost centre assignment. Every provisioned resource must be linked to a cost centre and an owner at creation, regardless of how it was created. Resources without ownership metadata are nearly impossible to clean up automatically later.
-
Transition (Deployment). The resource moves into active use. Configuration is validated, integrations are tested, and the resource is handed over to the operating team. Infrastructure-as-code tools like Terraform enforce consistency at this stage and reduce configuration drift.
-
Operation (Usage, Maintenance, and Optimisation). This is the longest stage and the one with the most cost impact. Rightsizing, patching, performance monitoring, and continuous cost review all happen here. AWS Compute Optimizer analyses up to 93 days of utilisation metrics to produce rightsizing recommendations refreshed daily. That kind of continuous analysis is what keeps operational costs from drifting upward over time.
-
Decline. The resource is still running but is no longer the preferred solution. Usage drops, support from the vendor narrows, or a newer service generation supersedes it. This stage is often invisible without active monitoring, which is why many teams miss it entirely.
-
Retirement (Decommissioning). The resource is shut down, data is archived or deleted, and dependencies are cleaned up. Automated decommissioning scripts tied to lifecycle policies make this repeatable and auditable.
Pro Tip: Build your exit plan at provisioning, not at retirement. Define the conditions that will trigger decommissioning before the resource is created. Teams that do this avoid ghost resources entirely.
How does lifecycle management drive cloud resource optimisation?
Good lifecycle management and cost control are the same thing, viewed from different angles. When you govern resources across their full lifespan, you prevent the three most common sources of cloud waste: overprovisioned instances, idle resources, and forgotten assets still accruing charges.
The Operation stage is where rightsizing delivers the most direct savings. Tools like AWS Compute Optimizer remove the guesswork by surfacing specific recommendations based on actual utilisation patterns. Without that continuous analysis, teams tend to leave instances at their original size indefinitely, even as workload patterns change.
| Outcome | With structured lifecycle management | Without structured lifecycle management |
|---|---|---|
| Rightsizing | Continuous, data-driven recommendations | Manual, infrequent, often skipped |
| Idle resource detection | Automated alerts and cleanup triggers | Discovered only during audits |
| Retirement execution | Scripted, policy-driven decommissioning | Ad hoc, frequently delayed |
| Cost centre accuracy | Assigned at provisioning via CMDB | Incomplete, leading to unallocated spend |
| Security compliance | Patching and deprecation tracked automatically | Gaps emerge as versions age |
Cloud compute inefficiencies compound over time. A single oversized instance is a minor issue. Hundreds of them, running unreviewed for two years, represent a material budget problem. Lifecycle management is the process that prevents that accumulation.
Pro Tip: Use your CMDB as the single source of truth for every cloud asset. Link each record to a cost centre and a business owner. This makes cost allocation accurate and gives automated cleanup scripts the ownership context they need to act safely.
What challenges do organisations face in managing the lifecycle effectively?
Most cloud teams are reasonably good at provisioning. The problems cluster at the other end of the lifecycle.
-
Neglected retirement. The retirement phase is the most overlooked stage in cloud resource management. Resources that should have been decommissioned months ago continue running because no one has formal ownership of the shutdown process.
-
Ghost resources. Focusing only on provisioning and operation without automated exit plans produces zombie resources that generate hidden costs and evade automated cleanups. These are harder to catch when tags or ownership metadata are missing.
-
Hardware generation lock-in. Failing to migrate from older instance families, such as AWS t2, locks teams into higher costs and prevents access to performance improvements in newer generations. This is a lifecycle failure, not a purchasing failure.
-
Multi-cloud visibility gaps. Tracking lifecycle status across AWS, Google Cloud, and Azure simultaneously requires automated asset inventory systems. Manual approaches break down quickly when resources span multiple accounts and regions.
-
Missing metadata. Resources created outside standard provisioning workflows, such as those spun up manually in a console, often lack the tags and ownership records that automated lifecycle tools depend on. One missing tag can block an entire cleanup workflow.
-
SDK and API deprecations. Ignoring lifecycle updates to software dependencies creates security exposure and compatibility failures. Workloads running on deprecated SDKs or API versions accumulate technical debt that becomes expensive to unwind.
"Teams that fail to track retirement dates proactively face unexpected service deprecations and increased spending. The cost is not just financial. Unplanned retirements cause operational disruption that takes engineering time to resolve."
Which tools best support automated lifecycle management?
The right tooling makes lifecycle management a background process rather than a recurring fire drill. The goal is to automate the transitions between stages so that human attention is reserved for decisions, not tracking.
CMDB and asset discovery
A Configuration Management Database is the backbone of lifecycle management. Modern CMDB solutions integrate with cloud APIs and infrastructure-as-code tools like Terraform to auto-onboard resources at creation. Every asset gets a record, an owner, a cost centre, and a lifecycle status from day one. Without this foundation, every downstream process, from rightsizing to decommissioning, operates on incomplete information.
End-of-life tracking
Azure's Service Retirement Workbook consolidates resource retirement schedules and migration plans into a centralised, filterable view. It shows which resources are approaching end-of-life and which migration paths are available. This kind of proactive visibility prevents the surprise retirements that cause unplanned engineering work.
Rightsizing and utilisation analysis
AWS Compute Optimizer is the standard tool for EC2 rightsizing on AWS. It analyses utilisation data and produces daily recommendations. Equivalent capabilities exist across other cloud platforms. The key is feeding these tools consistent utilisation data and acting on their output on a regular cadence, not just during quarterly reviews.
| Tool type | Primary function | Lifecycle stage served |
|---|---|---|
| CMDB with cloud API integration | Asset discovery, ownership assignment | Provisioning, all stages |
| End-of-life tracking dashboards | Retirement scheduling, migration planning | Decline, Retirement |
| Rightsizing engines | Utilisation analysis, instance recommendations | Operation |
| Tagging policy enforcement | Metadata completeness, cost allocation | Provisioning, Operation |
| Automated decommissioning scripts | Shutdown, cleanup, dependency removal | Retirement |
For idle resource management, automated detection tools flag resources that have had no meaningful activity for a defined period. Pairing these alerts with ownership data from your CMDB means the right person gets notified automatically, rather than the issue sitting unresolved in a backlog.
Pro Tip: Integrate your IaC pipeline with your CMDB so that every Terraform apply or CloudFormation deployment triggers an automatic asset record update. This closes the gap between what was deployed and what your inventory shows.
Key takeaways
Effective cloud resource lifecycle management is the single most reliable way to control cloud costs, because it governs every stage from provisioning to retirement rather than reacting to waste after it has already occurred.
| Point | Details |
|---|---|
| Six stages define the lifecycle | Planning, Provisioning, Transition, Operation, Decline, and Retirement each carry distinct cost and governance responsibilities. |
| Retirement is the highest-risk stage | Most cloud waste originates from resources that were never formally decommissioned. |
| CMDB is the foundation | Linking every asset to a cost centre and owner at provisioning enables every downstream automation. |
| Rightsizing requires continuous data | Tools like AWS Compute Optimizer analyse utilisation daily; acting on those recommendations consistently prevents cost drift. |
| Automation is not optional | Manual lifecycle tracking fails at scale. Automated workflows are the only way to maintain visibility across multi-cloud estates. |
Why the retirement phase deserves far more attention than it gets
Most engineering teams I work with have solid provisioning practices. Tagging policies exist. IaC pipelines are in place. Cost dashboards are configured. But ask those same teams what their formal retirement process looks like, and the answer is usually a shrug.
The retirement phase is where cloud cost discipline actually gets tested. Provisioning is exciting. Retirement is administrative. That asymmetry in attention is exactly why ghost resources are so common. A resource that was provisioned correctly, tagged correctly, and monitored correctly can still become a cost leak if no one pulls the trigger on decommissioning when the workload it served is discontinued.
The fix is not complicated. It is a process change, not a technology change. Define retirement criteria at provisioning. Set a review date. Assign an owner who is accountable for executing the shutdown. Automate the cleanup steps so that execution does not depend on someone remembering to do it.
Multi-cloud environments make this harder. Tracking lifecycle status across AWS, Google Cloud, and Azure simultaneously requires tooling that aggregates asset data into a single view. Teams that rely on native console tools for each platform will always have blind spots. A centralised CMDB with cloud API integrations is the only architecture that scales.
The organisations that manage their cloud costs most effectively are not necessarily the ones with the best discount strategies. They are the ones that treat lifecycle management as a continuous, automated workflow and hold engineering teams accountable for the full lifespan of every resource they create.
How Koritsu AI helps you manage cloud costs across the lifecycle
Cloud cost problems are almost always lifecycle problems in disguise. Koritsu AI combines continuous AI-driven spend analysis with hands-on expert advice to find the inefficiencies that standard cost dashboards miss. Kori, Koritsu's AI agent, surfaces waste at every lifecycle stage, from overprovisioned instances in the Operation phase to forgotten resources that should have been retired months ago. Koritsu's specialists then work directly with your engineering teams to act on those findings. You can see the kind of results this produces in the UK bidding platform case study, where structured lifecycle-aware optimisation delivered a 52% reduction in cloud costs. Koritsu charges only on savings delivered. Start with a free assessment to see where your lifecycle gaps are.
FAQ
What is the cloud resource lifecycle?
The cloud resource lifecycle is the end-to-end management framework that tracks a cloud asset through six stages: Planning, Provisioning, Transition, Operation, Decline, and Retirement. Managing each stage deliberately prevents cost waste and security gaps.
What are cloud resources?
Cloud resources are the computing assets provisioned from a cloud platform, including virtual machines, storage buckets, databases, networking components, and managed services on providers such as AWS, Google Cloud, and Azure.
Why is the retirement stage so often neglected?
Retirement lacks the visibility and urgency of provisioning, so teams deprioritise it. The result is ghost resources that continue accruing charges long after the workload they supported has been discontinued.
How does CMDB support cloud resource lifecycle management?
A CMDB assigns ownership, cost centre, and lifecycle status to every asset at provisioning. That metadata enables automated rightsizing, cleanup, and retirement workflows to operate without manual intervention.
What is rightsizing in the context of the cloud resource lifecycle?
Rightsizing is the process of matching instance size and type to actual workload requirements during the Operation stage. AWS Compute Optimizer analyses up to 93 days of utilisation data to produce daily rightsizing recommendations, reducing both cost and manual effort.