Fintech
Fintech Londrina: Otimização de £100K/mês em Cosmos DB
Descubra como a Koritsu ajudou uma fintech londrina a economizar £100K/mês corrigindo uma consulta mal configurada no Cosmos DB. Um estudo de caso de otimização de custos em banco de dados na nuvem.
Introdução
No mundo acelerado das fintechs, eficiência não é apenas um objetivo — é uma necessidade. Para uma fintech londrina, a conta crescente do Azure havia se tornado um dreno silencioso: £100.000 todo mês. Isso é mais do que algumas startups captam em rodadas de seed. E para uma empresa do porte delas, era um gasto significativo.
O Desafio
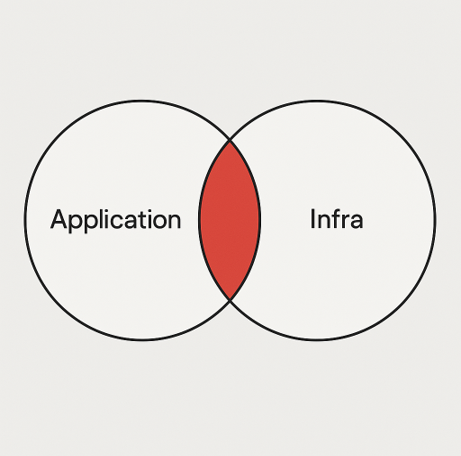
Quando a Koritsu AI entrou em cena, não enxergamos apenas uma fatura de nuvem — vimos um quebra-cabeça esperando para ser resolvido. Nossa primeira descoberta? Metade desse custo, £50.000 por mês, vinha de um único banco de dados Cosmos DB. Ora, £50k para um banco de dados não é incomum se você processa terabytes de dados para treinamento de IA ou transações globais. Mas aqui? Era diferente.Olhando apenas para a infraestrutura, os £50.000/mês seriam justificados — afinal, o consumo de DTU (CPU/memória) estava no limite, causando os altos custos. Mas é aí que o diferencial da Koritsu entra. Olhar apenas para a infraestrutura é como olhar para um caminhão lento e se perguntar por que ele não consegue ir mais rápido, quando o problema real é que ele está carregando peso demais.
A Descoberta
Na Koritsu, entendemos que é a aplicação que determina a carga — então, às vezes, o problema existe na interseção entre infraestrutura e aplicação. Nossa investigação profunda revelou o culpado: uma única consulta mal configurada, executando centenas de vezes por segundo.SELECT c FROM c WHERE c.data = 'JoihnDoe2018-02-01'À primeira vista, parecia inofensiva. Mas no Cosmos DB, um banco de dados NoSQL projetado para escalonamento horizontal, essa consulta era uma bomba-relógio financeira. Diferente dos bancos tradicionais que escalam verticalmente (aumentando o tamanho de uma única máquina), o Cosmos DB escala horizontalmente, distribuindo dados em partições.
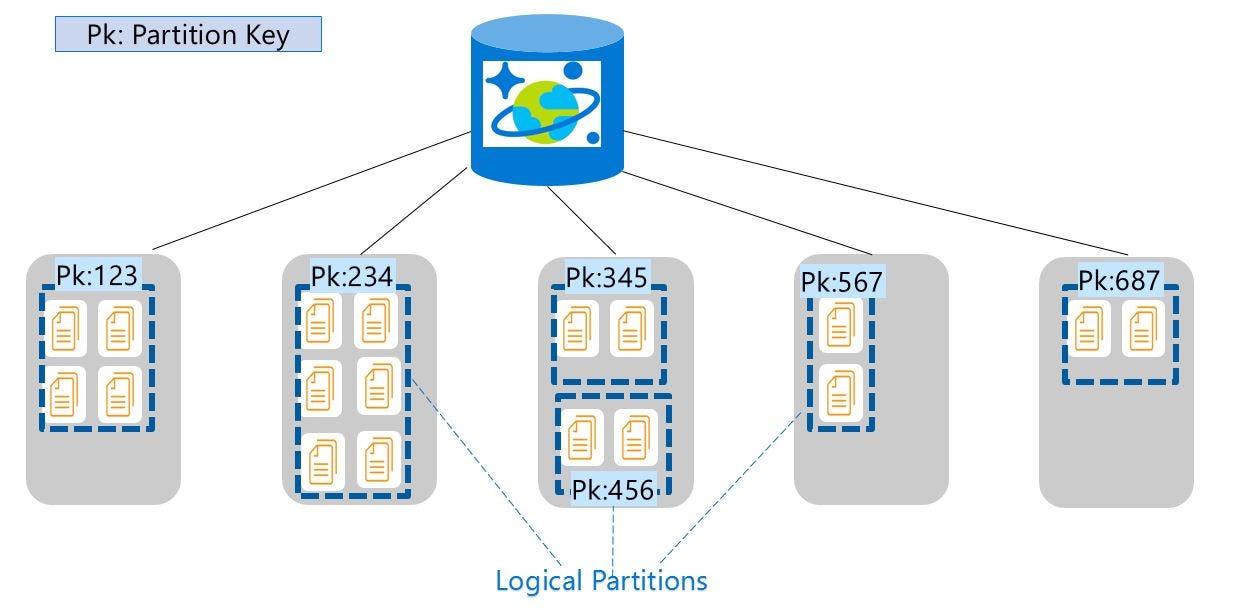
A Solução
E aí está o problema: se uma consulta não especifica em qual partição buscar, ela varre todas elas — como verificar cada sala de um arranha-céu para encontrar uma única chave. Era um problema exponencial. À medida que os dados cresciam, o custo também subia, drasticamente. Quando a equipe da fintech estava pronta para agir, a conta havia saltado para £150.000/mês.A correção? Surpreendentemente simples. Reestruturando o schema para que a consulta mirasse a partição correta, cortamos o custo de volta para £50.000 imediatamente. São £100.000 economizados todo mês, apenas entendendo a interseção entre infraestrutura e lógica de aplicação.